In this class I cover the basics of pre-processing and running machine learning models in PySpark. First, I review the concept of estimators versus transformers (this is an extremely important topic for the Databricks ML Practitioner Exam). I cover how to perform pre-processing steps including:
- One-Hot encoding
- Preparing categorical data for processing with StringIndexer
- Missing data imputation
- Rescaling features
- Inputting data into a model with VectorIndexer
Finally, I cover how to run a machine learning model and how to combine all the above steps into a single pipeline optimized for deployment.
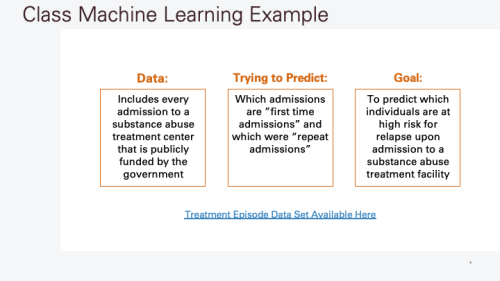
Data Is Available Here and Code Is Available Here











Suggested Reading:
- Spark: The Definitive Guide, Chapters 24-27 (p. 401-488)
- Learning Spark, 2nd Edition, Chapter 10 (p. 285-321)
